在本文中,本土独角兽依图科技提出了一个小而美的方案——ConvBERT,通过全新的注意力模块,仅用 1/10 的训练时间和 1/6 的参数就获得了跟 BERT 模型一样的精度。相比费钱的 GPT-3,这项成果可让更多学者用更少时间去探索语言模型的训练,也降低了模型在预测时的计算成本。本文已被 NeurIPS 2020 接收。
今年 5 月,Open AI 发布了非常擅长「炮制出类似人类的文本」的 GPT-3,拥有破天荒的 1750 亿参数,一时被业界视为最强大的人工智能语言模型。
可是,训练成本极高,难以普及,也成了 GPT-3 成功背后的不足。相对于通用的计算机视觉模型,语言模型复杂得多、训练成本也更高,像 GPT-3 这种规模的模型只能是工业界才玩得起。
深度学习「教父」LeCun 也说:「试图通过扩大语言模型的规模来建造智能应用,就像建造一架飞往月球的飞机。你可能会打破高度记录,但是登上月球其实需要一种完全不同的方法。」
本土独角兽依图科技最近在人工智能界顶会 NeurIPS 上提出了一个小而美的方案——ConvBERT,通过全新的注意力模块,仅用 1/10 的训练时间和 1/6 的参数就获得了跟 BERT 模型一样的精度。相比费钱的 GPT-3,这项成果可让更多学者用更少时间去探索语言模型的训练,也降低了模型在预测时的计算成本。
今年的 NeurIPS 创纪录接收并审阅了来自全球的 9454 篇论文,但最终仅 1900 篇论文被收录,录用率为 20.09%,创历年来接受率最低纪录。问题不够令人兴奋者,不可收也。被收录的论文更显珍贵。
依图的这篇论文提出了基于区间的新型动态卷积,在自然语言理解中证明有效,在计算机视觉领域也可使用。这是依图继 ECCV 2020 之后,连续开放的第二项主干网络基础性改进工作。

预训练语言理解新模型 ConvBERT,超越谷歌 BERT
最近 BERT 这一类基于预训练的语言理解模型十分流行,也有很多工作从改进预训练任务或者利用知识蒸馏的方法优化模型的训练,但是少有改进模型结构的工作。依图研发团队从模型结构本身的冗余出发,提出了一种基于跨度的动态卷积操作,并基于此提出了 ConvBERT 模型。
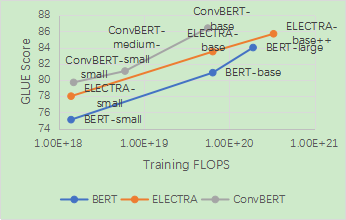
这一模型在节省了训练时间和参数的情况下,在衡量模型语言理解能力的 GLUE benchmark 上相较于之前的 State-of-the-art 方法,如 BERT 和 ELECTRA,都取得了显著的性能提升。其中 ConvBERT-base 模型利用比 ELECTRA-base 1/4 的训练时间达到了 0.7 个点的平均 GLUE score 的提升。
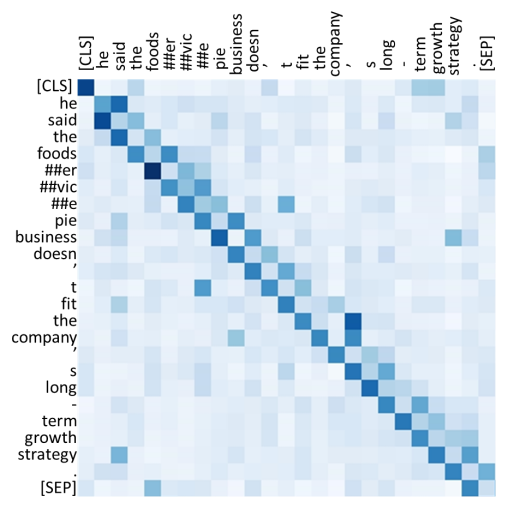
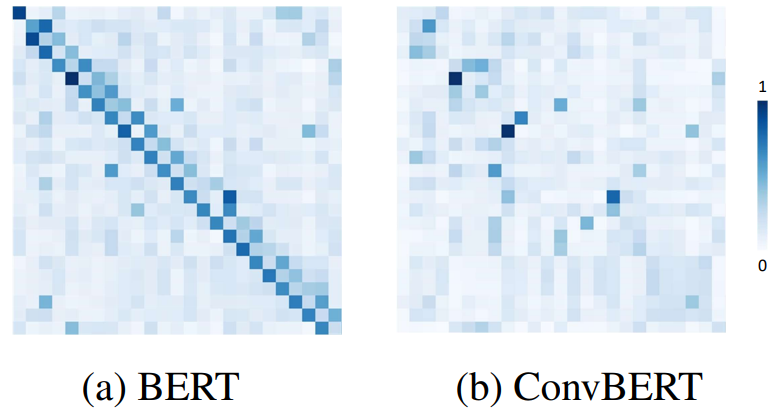
之前 BERT 这类模型主要通过引入自注意力机制来达到高性能,但是依图团队观察到 BERT 模型中的 attention map 有着如下图的分布(注:attention map 可以理解成词与词之间的关系),这表明了大多注意力主要集中在对角线,即主要学习到的是局部的注意力。这就意味着其中存在着冗余,也就是说很多 attention map 中远距离关系值是没有必要计算的。
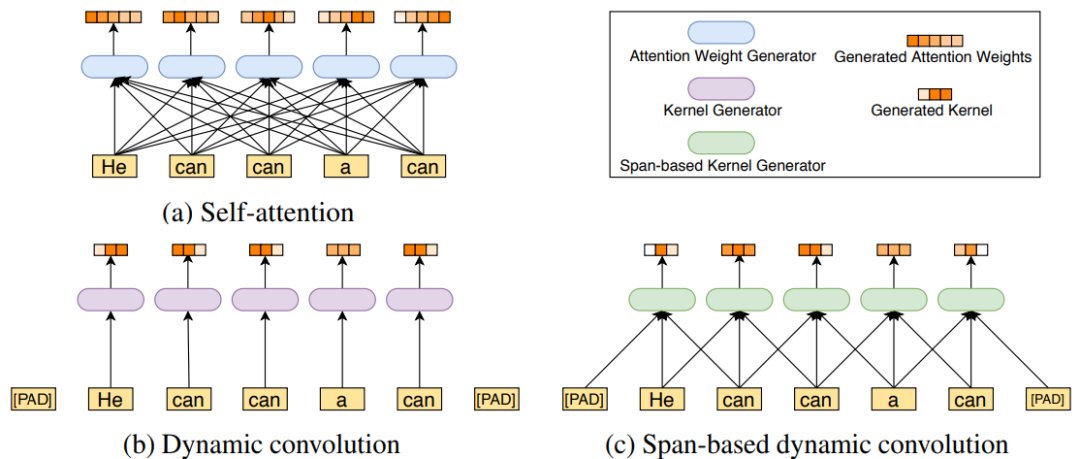
于是依图团队考虑用局部操作,如卷积来代替一部分自注意力机制,从而在减少冗余的同时达到减少计算量和参数量的效果。
另一方面,考虑到传统的卷积采用固定的卷积核,不利于处理语言这种关系复杂的数据,所以依图提出了一种新的基于跨度的卷积,如下图所示。原始的自注意力机制是通过计算每一对词与词之间的关系得到一个全局的 attention map。
此前有文章提出过动态卷积,但其卷积的卷积核并不固定,由当前位置的词语所代表的特征通过一个小网络生成卷积核。这样的问题就是在不同语境下,同样的词只能产生同样的卷积核。但是同样的词在不同语境中可以有截然不同的意思,所以这会大大限制网络的表达能力。
基于这一观察,依图提出了基于跨度的动态卷积,通过接收当前词和前后的一些词作为输入,来产生卷积核进行动态卷积,这在减少了自注意力机制冗余的同时,也很好地考虑到了语境和对应卷积核的多样性。
基于跨度的动态卷积,同时减少原模型冗余和参数量
具体而言,引入了一个轻量卷积的运算操作,
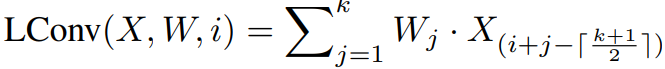
其中X∈R^n×d 为输入的特征,而W∈R^k 则是卷积核,k 为卷积核的大小。轻量卷积的作用是将输入的每个词对应的特征附近的 k 个特征加权平均生成输出。在此基础上,之前提到的动态卷积可以写作
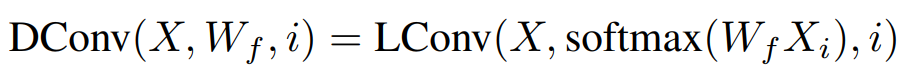
此处卷积核是由对应的词的特征经过线性变换和 softmax 之后产生的。为了提升卷积核对于同一词在不同语境下的多样性,依图提出了如下的动态卷积
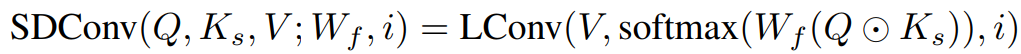
此处,输入 X 先经过线性变换生成Q和V,同时经过卷积生成基于跨度的K_s,由Q⊙K_s经过线性变换以及 softmax 来产生卷积核与V进一步做轻量卷积,从而得到最终的输出。
在基于跨度的卷积的基础上,依图将其与原始的自注意力机制做了一个结合,得到了如图所示的混合注意力模块。
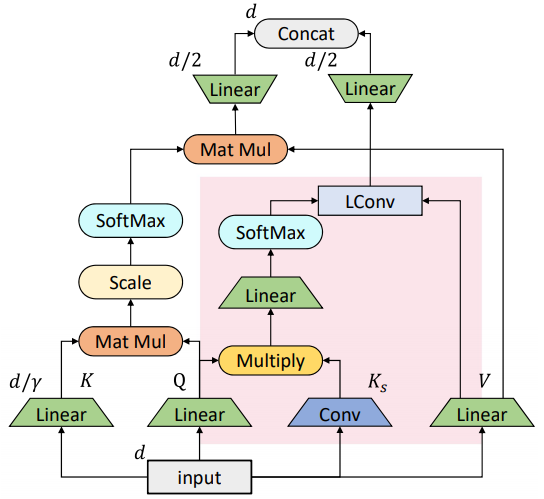
可以看到,被标红的部分是基于跨度的卷积模块,而另一部分则是原始的自注意力模块。其中原始的自注意力机制主要负责刻画全局的词与词之间的关系,而局部的联系则由替换进来的基于跨度的卷积模块刻画。
从下图 BERT 和 ConvBERT 中的自注意力模块的 attention map 可视化图对比也可以看出,不同于原始的集中在对角线上的 attention map,ConvBERT 的 attention map 不再过多关注局部的关系,而这也正是卷积模块减少冗余的作用体现。
对比 state-of-the-art 模型,ConvBERT 所需算力更少、精度更高
为分析不同卷积的效果,依图使用不同的卷积得到了如下表所示的结果
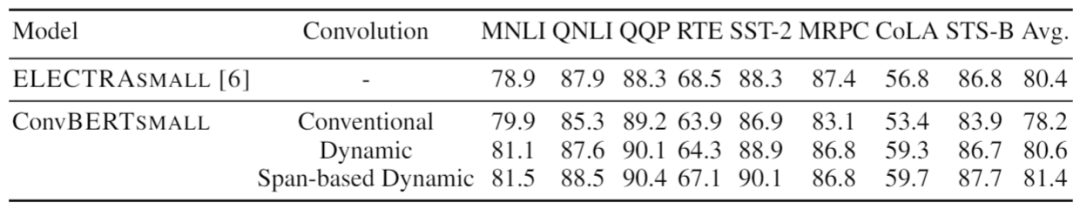
可以看出在模型大小一致的情况下,传统卷积的效果明显弱于动态卷积。并且,本文提出的基于跨度的动态卷积也比普通的动态卷积拥有更好的性能。
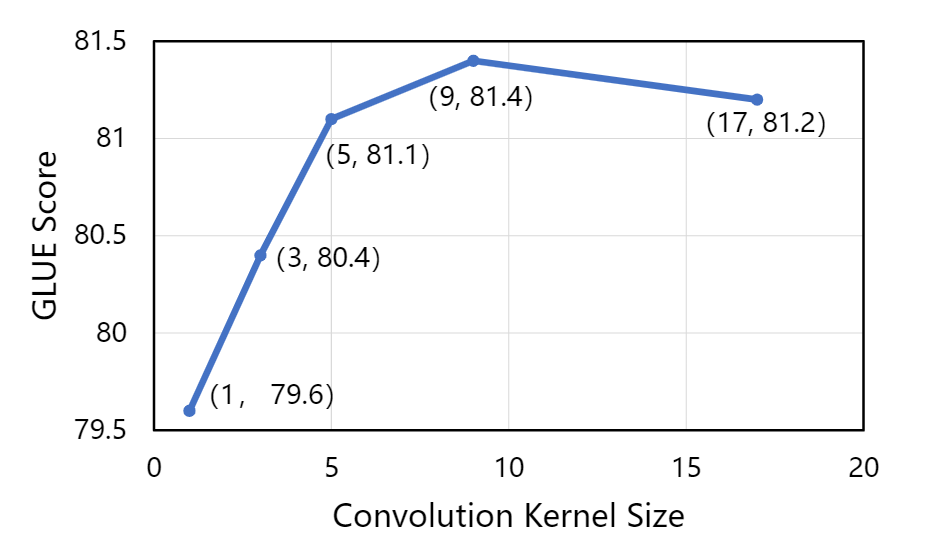
同时,依图也对不同的卷积核大小做了分析。实验发现,在卷积核较小的情况下,增大卷积核大小可以有效地提高模型性能。但是当卷积核足够大之后提升效果就不明显了,甚至可能会导致训练困难从而降低模型的性能。
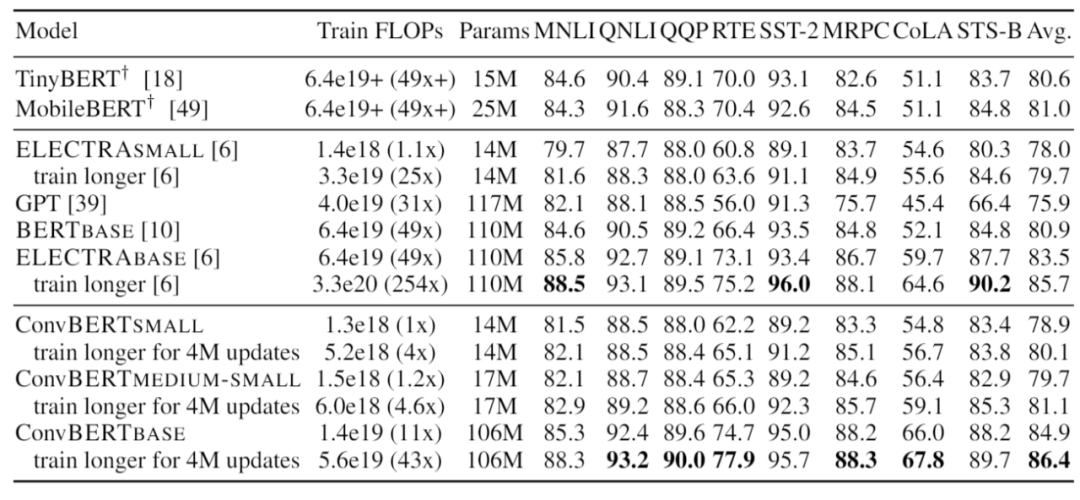
最后,依图将提出的 ConvBERT 模型在不同的大小设定下与 state-of-the-art 模型进行了对比。值得注意的是,对小模型而言,ConvBERT-medium-small 达到了 81.1 的 GLUE score 平均值,比其余的小模型以及基于知识蒸馏的压缩模型性能都要更好,甚至超过了大了很多的 BERT-base 模型。而在大模型的设定下,ConvBERT-base 也达到了 86.4 的 GLUE score 平均值,相比于计算量是其 4 倍的 ELECTRA-base 还要高出 0.7 个点。
您可以复制这个链接分享给其他人:https://www.yitutech.com/node/879





